图源:unsplash
唯一的ID使开发人员能够正确识别、保存和检索数据对象,并使数据对象参与到复杂的关系模式中。在应用程序开发周期中,程序员总会遇到要处理生成唯一的标识符这项任务。
这些独特的ID是如何生成的呢?哪种方法在不同的负载规模下最有效?ID如何在多个计算节点竞争下一个可用ID的分布式环境中保持唯一性?从小型单节点,到Twitter级别,本文笔者就将介绍三种最常见的技术。
通用唯一标识符——UUID
通用唯一标识符(UUID)这个概念大家不会陌生,它在软件中已经使用多年了。它是一个128位的数字,以受控和标准化的方式生成时,能够提供非常大的键空间,几乎消除了冲突的可能性。
UUID是由几个不同部分组成的合成ID,例如时间、节点的MAC地址或MD5散列的命名空间。为了适应所有这些组合,多年来,UUID规格已经发展出多个版本,特别是版本1和版本4。
根据数据和业务域的不同,一些开发人员可能会对其他版本感兴趣。处理128位数字并不是最适合开发人员描述信息的方式,因此UUID通常以规范文本形式表示,其中16个八位字节转换为32个十六进制字符,用连字符分隔,总共36个字符:

UUID样本-版本4
UUID最有趣的特性是其可以单独生成,且仍能保证在分布式环境中的唯一性。基本的ID生成算法并不复杂,也不需要任何同步(至少是低至100纳秒级别),可以并行执行:
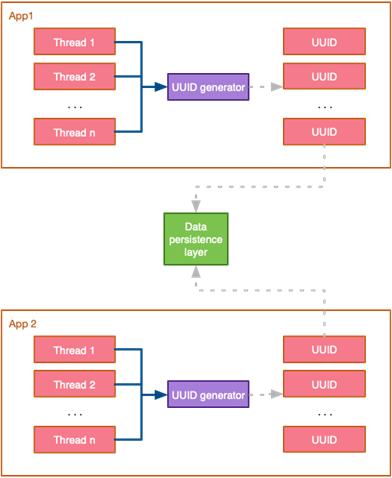
分布式环境中生成唯一ID
能够自生成唯一性的内在属性,使得UUID成为分布式环境中最常用的ID生成技术之一。但UUID需要额外的存储空间,这可能会对查询性能产生负面影响。
持久层生成的ID
如果不想在应用程序级别生成唯一ID时,另一种常见的方法是用永续性储存体来处理。
最近所有的RDBMS都提供了某种列数据类型,开发人员能够委托它们生成唯一标识符。MongoDB提供ObjectID,MySQL和MariaDB提供AUTO_INCREMENT,MS-SQL-Server提供IDENTITY,等等。执行不同的数据库,ID的实际表现会有所不同,但唯一性的含义保持不变。
持久层生成的ID缓解了必须在应用程序代码中生成唯一ID的问题。但如果操作一个大型数据库集群,且有非常繁忙的应用程序在前,这种方法可能就无法满足需要了。
还有另一个问题:如果不往返数据库,则生成的ID对于代码来说是未知的:
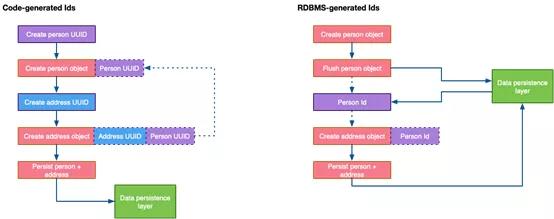
RDBMS vs代码生成ID
上图中,额外往返于RDBMS可能会减慢应用程序的速度,可能使代码不必要地复杂化。然而,无论使用的是否是基础RDBMS产品,现代ORM框架都有助于以标准化的方式完成这项工作。
ID服务器还是Snowflake ID
ID服务器负责为分布式基础设施生成唯一的ID。根据ID服务器执行功能的不同,可以是创建ID的单个服务器,也可以是每秒创建大量ID的服务器集群。
Twitter就不用我介绍了吧,平均每秒有9000条推特产生,峰值高达每秒143199条。Twitter需要一个解决方案,扩大其庞大服务器基础设施的规模,生成高效的存储ID。
图源:unsplash
这就是Twitter推出Snowflake计划的原因:Snowflake是一种能大规模生成唯一ID号的网络服务,同时具备一些基础的保证。
Twitter之前使用过一种每个进程每秒至少生成10000个ID且响应速度小于2ms的服务器。ID服务器之间不需要任何网络协调,生成的ID应大致按时间顺序排列,为了将存储保持在最低限度,生成的ID必须紧凑。
为了解决上述项目,Twitter开发了Snowflake项目作为用Scala编写的Thrift服务器。生成的ID包括:
· 时间——41位(毫秒精度)
· 配置的机器ID——10位
· 序列号——12位(每台机器每4096转一次)
虽然现在Snowflake项目已经结束,以一个更广泛的项目TwitterServer取而代之,但是分布式ID生成器工作的基本原则仍然适用。由于每个生成器具有独立性,Twitter能够根据需要扩展其基础设施,不会产生由于集群同步和协调而造成额外的延迟。
使用ID服务器的解决方案与代码生成ID的运作方式类似:
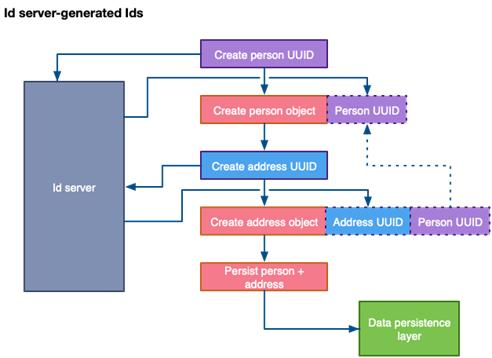
ID服务器生成ID
你会发现,其性能仍然会由于往返于ID服务器而降低,但因为不涉及复杂的数据库操作,这一额外的延迟比将对象刷新到RDBMS要短得多。ID服务器提供了一个中间解决方案,使开发人员能够控制生成唯一ID的方式与地点,无需引入复杂的、导致高延迟的基础设施。
对于最终需要保存数据的所有应用程序来说,生成唯一标识符都是必要步骤。本文讨论了三种常用的方法:UUID——本地生成ID,持久层驱动ID——集中创建ID,以及SnowflakeID——作为网络服务生成ID。
没有一劳永逸的解决方案。在应用程序中,选择生成唯一ID的方法需要考虑数据、持久性选项和网络基础设施等各个方面,这样才能挑到符合你需求和想法规模的方案。